Emacs風ATOKの設定ファイルと効率的な連接変換方法
以前、XKeymacsとATOKを合わせて使う方法を紹介したが、英語キーボードに換装したことにより若干状況が変わったので、再び設定ファイルを調整した。ネットワークへのバックアップもかねて、再び公開してみる。
今回の設定ファイルでは、無変換キーなどが無くなってしまった都合上、「英字入力ON/OFF」をC-]に割り当てている。TELNETなどのアプリケーションではエスケープに使用することもあり、若干危険なキーバインドだが、最近ではまず使わないので気にしないことにした。むしろ、IMEのトグルであるC-\の隣にあることが、直感的にキーを押す際には重要なのである。
また、IMEのトグルをC-\で行うキーバインドは、今回はATOKで定義していない。かわりに、窓使いの憂鬱でC-\をIMEのトグルとして定義している。これはすべてのアプリケーションがC-\をIMEのトグルとして認識してしまうと、SSHクライアントなどで不都合が起こるからだ。入力がATOKに食われてしまい、リモートに伝わらなくなると、リモート側のIMEをトグルできなくなってしまう。窓使いの憂鬱ならばアプリケーションごとに個別の設定を行うことができるため、基本的にはC-\をM-GraveAccentとして定義し、必要なアプリケーションではそれを解除することで、SSHクライアントなどに対応することが可能になるわけである。なお、M-GraveAccentとし定義しているのは&SetImeStatusがMSNメッセンジャーなど、一部のアプリケーションではうまく動かないからだ。どうも「詳細なテキストサービス」との関連があるようだが、こちらをOFFにしてもだめらしい(が、「詳細なテキストサービス」は窓使いの憂鬱を使用する場合はOFFにしておいた方がいいようだ)。
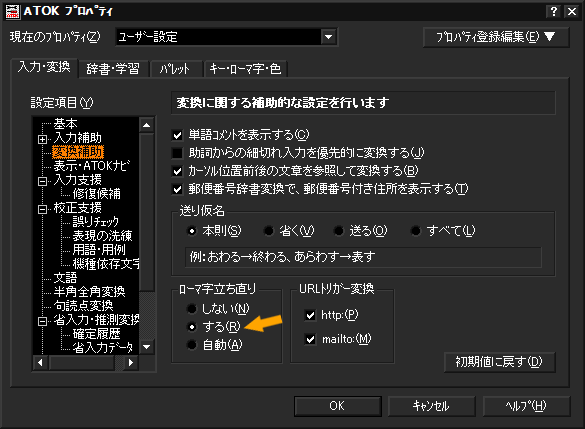
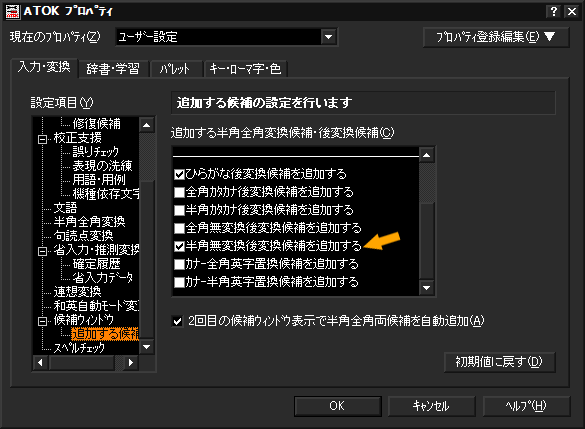
ところで、最近ATOKをかなりいじっているのだが、アルファベット混じりの文章を入力を効率化するには「ローマ字立ち上がり」とAIの学習を有効活用するのがいいらしい。プロパティの「変換支援」にあるローマ字立ち上がりをONにし(図1)、変換候補に「半角無変換後変換」を追加しておく(図2)。
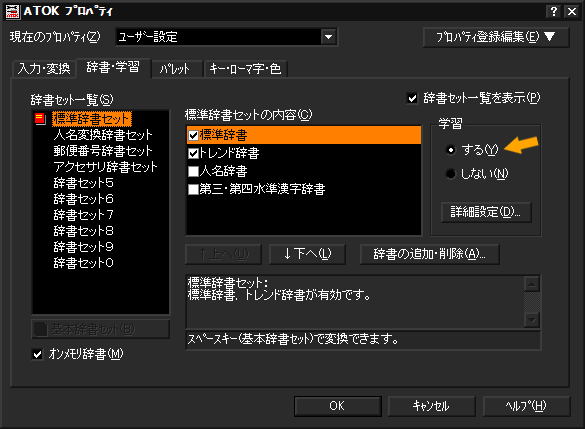
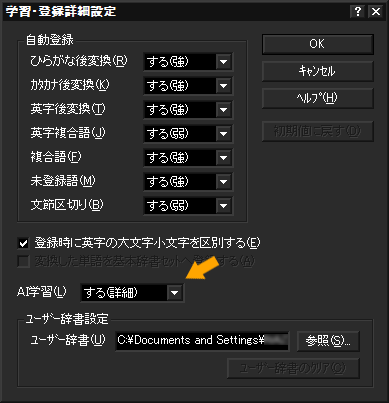
さらに、「辞書・学習」でAIの学習を「する」にセットし(図3)、詳細設定からAI学習を「する(詳細)」にしておく(図4)。これらの設定を行うと、「英字入力」のON・OFFをいちいち切り替えなくても、アルファベットを含んだ文章を効率的に連接変換できるようになる。
たとえば、「a t o k w o t u k a u」と順番に入力すると入力中の文章は「あとkをつかう」となるが、この状態でスペースを押すと「ATOKを使う」と変換されるようになる。最初はうまく変換されないかもしれないが、C-LとC-Kで文節区切りを調節し、半角英数の候補を選べばよい(このために半角無変換誤変換を候補に追加した)。1度入力した英単語はAIが辞書に追加してくれるので、次からは1発で変換されるようになる。
なお、「a t o k a g e r u(ATOKあげる)」のように、子音で終わる英単語の後に母音が続く文章の場合「あとかげる」となってしまい、C-LとC-Sではうまく文節の調節ができない。この場合はそれぞれにShiftを足してC-S-LとC-S-Kを入力すればローマ字単位で調整できる。
こんな感じで辞書が成長してくると、いちいちC-]で入力モードを変更せずともスペース1発で変換できるので、なかなか楽である。暇な人は挑戦してみるといいかもしれない。